
[Two Cents #58] Generative AI 투자 기회에 대한 생각
혹은, Generative AI 투자 Thesis
시작하며
몇 개월간 Generative AI 분야 rabbit hole을 파면서, 지속적으로 “투자자로서 특히 앞으로 10년간 어떤 기회가 있을까?”에 촛점을 맞추어 고민해 왔다.
90년대 후반 인터넷이 등장하면서 새로운 큰 흐름이 만들어지고 시장 구조가 완전히 새로 짜인 것과 같은 규모의 큰 변화가 AI에 의해서 일어날 것이라는 것은 너무 분명하였다. NfX에서 “Web3라는 용어를 Crypto에 사용한 것은 너무 조급하였다. AI를 Web3라고 불러야 했다”고 할만큼 큰 변화가 만들어질 것이다. 어쩌면 AI를 Web3라고 부르는 것조차 과소평가하는 것 일 수 있다는 생각도 들 정도.
지금 생각으로는, Web 1.0에 버금가는, 어쩌면 그보다 더 큰 변화가 만들어질 것이라는 판단이다. 트위터에서 어느 투자자가 “지난 20년간 Open Web의 시대의 의미는, 새로 등장할 ‘AI의 시대’에 필요한 학습 데이터를 온라인으로 준비해 두는 기간으로서 그 역할을 다 한 셈”이라고 할 정도로.
하지만 자꾸 생각의 틀이 현재의 시장 구도, 경쟁 상황 등에 의해 제한되는 느낌이어서, 통상 10년의 투자 사이클의 VC 투자자로서 최대한 멀리 보는 시각을 가지려고 의도적으로 노력했다. 더밀크 손재권 대표가 Web3에 대한 시각을 공유해 달라고 요청하면서, “90년대 후반 인터넷이 등장했을 때 시장의 구조가 어떻게 변화하였는 지에 비추어 설명해 주면 가장 좋은 참고가 될 것 같다”라는 말이 이번에도 딱 맞을 정도로.
하여, 이번에도 같은 시각에서 AI가 가져 올 시장의 변화를, 가능한 한 ‘메타 구조’ 시각으로 보고 90년대 인터넷 도입기에 일어났던 일들과 비교하면서 해석해 보려고 한다.
새로운 기술에 의한 시장 변화에 대한 시각
PC, 인터넷, AI 등과 같은 disruptive technology의 등장은, 이전까지의 경쟁의 룰을 한순간에 리셋해 버리고 완전히 새로운 판 짜기가 필요한 ‘reset moment’라고 할만 하다. 완전히 새로운 판을 만들어 버리는 제품이 등장하면, 기존의 룰은 무의미해지고 새로운 룰에 의해 만들어지는 새로운 시대가 탄생한다.
이번에는 Generative AI가 그 역할을 하게 될 것이 분명하다.
이러한 disruptive technology에 의한 reset moment에서는 일반적으로 아래의 3–4단계를 거치는 패턴을 보여 왔다. 이는 90년대 후반의 인터넷 전환기 뿐 아니라, 18세기 산업혁명이 시작된 이후 300여년간 여러 번 반복해서 일어 났던 과정이기도 하다. (전기 모터 보급으로 기존 수력 및 증기 기관 체제에서 만들어진 동력전달축 중심의 수직적 생산 설비 구조가 수평적으로 분산화될 수 있었던 과정, 그리고 이로 인해 가능해진 대규모 조직을 운용하기 위하여 계층 구조의 조직 운용 방식이 등장한 과정, 자동차가 기존 마차의 운용 방식을 넘어서는 장거리 운송 수단화한 것 등이 그 예라고 할 수 있다)
기존 방식에 새 기술을 적용하는 시도 & 새 기술.방식에 의한 ‘장난감 같은’ 시도의 혼재
새로운 기술, 방식에 맞는 새로운 모델, 비즈 모델의 등장 (’2세대 모델’)
‘2세대 모델’에 기반한 완전히 새로운 산업 구조의 구축
(1) 기존 방식에 새 기술을 적용하려는 시도 & 새 기술에 의한 ‘장난감 같은’ 시도의 혼재
90년대 후반에는, (1) 기존 매체 (예: 신문)을 인터넷으로 그대로 옮기려는 시도, (인쇄 매체 광고와 똑 같은 방식의) display 광고 등이 있었고, (2) ‘장난감 같은’ 새로운 시도로서 Virtual Museum, Virtual 쇼핑몰 (심지어 3D) 등이 있었다.
그러다 보면 그 중 사용자 기반과 moat를 찾아 내는 것이 몇 개 등장한다.
대개 기존 방식으로 가능하지 않거나, 가능하기는 하지만 friction, pain point가 큰 부분을 새로운 방식으로 해소하면서 열광적인 초기 사용자들이 몰리는 경우이다. 90년대 후반 국내에서는 다음 한메일, 다음 카페가 그러한 첫 번째 히트 서비스였다. (미국에서는 초기 인터넷 시장에 Yahoo! 디렉토리 서비스, (한메일의 벤치마크가 된) Hotmail, GeoCities 등이 있었다.)
(2) 새로운 기술, 방식에 맞는 새로운 모델, 비즈모델의 등장 (’2세대 모델’의 등장)
그러나, reset moment가 진정한 잠재력을 최대한 발휘하는 것은, 새로운 기술, 방식에 맞는 새로운 제품, 서비스 및 비즈니스 모델이 새로 만들어지면서 부터 이다.
완전히 새로운 방식의 서비스이든 (아마존과 같이) 전통적 구조와 같은 모델이든, 기본적으로 모든 비즈니스의 기반은 소비자의 욕구를 충족시키고 소비자는 이에 상응하는 댓가를 지불하는 기본 경제 구조에서부터 나온다. 아마존과 같이 소비자가 직접 지불하는 형태일 수도 있고, (새로운 인터넷 경제를 가능하게 한 ‘키워드 광고’이든, 지금 페이스북에 보편화된 ‘퍼포먼스 마케팅’이든) 모두 소비자의 ‘구매 의도’에 기반하여 그 구매의도로 미래에 지불할 금액의 일부를 ‘광고비’로 먼저 지출하는 모델이든.
그렇기 때문에 이러한 경제 구조의 기반 모델이 이후에 만들어진 산업 구조에 큰 영향을 미치는 것은 당연하다.
90년대 후반에는, (GoTo.com/오버추어가 발명한) 키워드 광고 모델, 그리고 (세이클럽이 발명한) 디지털 아이템 모델이 그 역할을 하는 두 가지 핵심 모델이었다고 본다. 이 두 모델의 등장으로, 이전 방식으로는 가능하지 않은 새로운 경제 모델의 만들어지면서, 검색과 온라인 서비스 (게임 포함) 분야에 기존에는 없던 완전히 새로운 서비스/경제 모델이 등장하고, 이를 통해 이후에 등장하는 모든 온라인 서비스을 받쳐 주는 경제 구조가 만들어지게 되었다.
(3) ‘2세대 모델’에 기반한 완전히 새로운 산업 구조의 구축
‘2세대 모델’이 등장하면서 이 기반의 새로운 경제 구조가 만들어지면, 이제 이전 구조에서 상상할 수 있는 것과는 완전히 다른 제품, 서비스, 비즈 모델, 경제 구조가 만들어지게 된다.
2010년을 전후한 10–20년 기간 동안 인터넷 및 모바일의 보편화 과정에서 우리 일상 생뫌 모든 면에서 만들어지고 보편화된 소셜 서비스, 모바일 서비스를 보면, 90년대 후반 인터넷이 도입되기 시작한 시기에는 상상할 수 없었던 완전히 새로운 제품, 서비스가 만들어지고, 또 이를 기반으로 완전히 새로운 경제 구조가 생겨나는 것을 관찰할 수 있다.
싸이월드, 페이스북, 우버 등의 소셜, 모바일 서비스가 등장하고, 이를 기반으로 Gig Economy, Creator Economy 등 기존에 가능하지 않았던 새로운 경제 구조가 만들어지는 과정을 통해 보아 왔듯이.
(4) 또 하나의 방식 — “변하지 않는 소비자의 니즈, 욕구를 찾아서”
이 과정에서 “10년 후에도 변하지 않을 소비자 니즈, 욕구를 찾아서 이를 만족시키는 비즈니스”가 또 다른 방식의 중요한 성공 방정식이 가능함을 아마존이 증명하기도 하였다. “가장 좋은 제품을, 가장 싸게, 가장 편리하게 사는 것”이 소비자의 영원히 변하지 않을 니즈라는 점에 집중하여 지난 30여년간 한결같이 이 value prop에 부합하는 서비스를 구축한 것이 지금의 아마존.
Generative AI 시장에 비추어 보면
이러한 관찰에 비추어 Generative AI 시장이 어떻게 형성되어 갈지 상상해 보자면,
가장 먼저, 쉽게 생각해 내고 쉽게 만들 수 있는 (많은 경우 2–3명이 2–3주 내에 만들어서 런칭 가능한) 서비스들이 지금 하루에도 수십개씩 생겨나고 있다. 이러한 ‘low-hanging fruit’ 서비스는 수천, 수만종 생겨날 것이고, 당연히 이들 대부분은 생존하지 못하고 시장에서 사라질 것이라고 본다.
Jasper, Lensa 등으로 대표되는 이러한 서비스가 어떻게 진화할 지에 대해서 두 가지 상반된 시각을 가질 수 있다.
공통의 FM 인프라 기반으로, 특정 도메인에 대한 data moat를 구축하고 대상 시장의 workflow 기반 소비자 가치를 창출함으로써, 사용자 기반 및 data moat를 구축하면서 성장해 가는 전형적인 SaaS 스타트업 플레이북. 이 사용자 기반 및 data moat 기반으로 계속 성장이 가능한 모델
ChatGPT 기능에 대한 단순한 UX layer 혹은 UX arbitrage에 그치는 수준. 장기적으로 사용자 기반 및 data moat를 구축하지 못 한다면, UX arbitrage에 그치고 장기적으로 sustainable하지 않음
이들 중 해당 veritical 및 workflow에 잘 맞추어 사용자의 니즈를 잘 만족시키면서 ‘사용자를 확보’하고, 이 과정에서 고유 데이터를 확보하여 ‘data moat’를 확보하는데 성공하는 서비스는 (다음 한메일, 다음 카페 같이) 초기 시장 진입자 중에서 살아 남아 major로 성장할 수 있을 것이다.
이러한 기간이 지나면서 (3–5년 정도 될 것으로 예상하지만, 더 짧아질 가능성도 아주 높은) 소위 ‘AI native’한 ‘2세대 모델’이 등장할 것이라고 예상된다.
이 ‘2세대 모델’이 어떤 형태로, 어떤 비즈 모델로 운용될 지에 대해서는 지금은 전혀 예측할 수 없으나, 몇 가지 상상의 나래를 펼쳐 보자면: (과거의 역사를 보면, 이렇게 큰 변화의 초기에 상상하였던 방향이 실제로 똑 같이 일어났던 경우가 별로 없기는 하다)
에이전트 모델: 초기에는 챗봇 에이전트의 형태를 띌 가능성도 높지만, 그보다 한 단계 더 나아가 (Adept ACT-1 모델과 같이) 사용자가 원하는 것을 얻기 위하여, (‘일련의 클릭/액션 단계들’을 거치는 방식이 아닌) 에이전트에게 자연어 텍스트 내지는 자연어 음성으로 원하는 바를 이야기하면, 에이전트가 필요한 웹 서비스, 데이터베이스, 툴 등을 사용하여 원하는 결과를 만들어 오는 방식
embedded/ambient 모델: 에이전트 모델이 진화하면, Siri, Alex와 같은 음성 Assistant가 원래 목표로 삼았던 ‘일상 생활에 내장된 ambient 서비스’ 형태로 진화할 것이다. 내가 있는 곳 (PC, 모바일, 거실, TV 앞, Alexa 스피커, 자동차 등) 어디에서든 내가 원하는 것을 입력 혹은 말하면, 필요한 것을 ‘실행’해 주는. 이 때, 실제 서비스를 실행하는 back-end는 기존 웹서비스의 조합이 되기 보다는, 새로운 형태의 ‘backend-only’ 플랫폼 형태로 제공될 수도 있다. 비유하자면, Amazon에서 front-end를 제외한 back-end 시스템.
미리 예측하는 모델: (아마존이 구매 행태 데이터에 기반하여 구매가 일어날 제품을 주문 전에 미리 가까운 배송 센터로 배송하듯이) 사용자가 원할 듯한 내용을 미리 제시
어느 시나리오든지 지금 우리가 익숙한 웹, 모바일 환경과는 아주 다른 방식으로 동작하는 AI-native 환경으로 진화할 가능성이 높고, 이 환경에 맞는 서비스 모델, 비즈니스 모델, 경제 모델이 등장, 발전할 것이라고 본다.
90년대 후반의 예에 비추어 볼 때, 앞으로 몇 년간 ‘2세대 모델’의 초기 모습이 등장하고 이후 10~20년간 이 새로운 ‘2세대 모델’을 기반으로 완전히 새로운 유형, 방식의 제품, 서비스들이 등장하기 시작할 수 있다.
특히 우리가 미래를 예상할 때 “단기적으로는 아주 낙관적이고, 장기적으로는 아주 비관적”이 되는 경향이 강한 만큼, 5~10년 이후 AI에 의한 변화를 예상할 때 지금 추정할 수 있는 것보다 더 큰 변화를 가정할 필요가 있다.
그럼에도 늘 기존에 없던 새로운 서비스만이 시장을 장악하지는 않을 것이다. 아마존의 예에서 보았듯이, 어느 경우에도 ‘소비자의 늘 변하지 않는 니즈’는 가장 원초적인 형태로 존재할 것이고, ‘2세대 모델’ 방식으로 이 니즈를 충족시켜 주는 제품, 서비스가 시장을 만들고 리드해 나갈 것이다.
이러한 전망 기반으로, 투자자로서는 향후 3–5년 시장, 기술의 흐름을 주의깊게 관찰하며 소위 ‘2세대 모델’이라고 할 수 있는 것이 새로 등장하는 시기와 형태, 이후 이를 기반으로 비즈니스가 발전하는 과정을 놓치지 않는 것이 중요한 역할이 될 것이다. 어찌 보면 너무 당연한 이야기지만, 이 inflection point를 놓치지 않고 이에 따른 흐름의 변화에 맞추어 투자 thesis를 유지하는 것이, 향후 10년간의 AI 투자에서 가장 중요한 turning point가 될 수 있다고 본다.
향후 5년간 투자 기회에 대한 생각
이러한 가정 하에서 최선을 다하여 향후 3~5년 투자 기회를 전망해 보자면:
1. FM 인프라
Gen AI 시장의 가장 중요한 인프라는 (주로 LLM 중심의) Foundation Model (FM) 인프라가 될 것이다. 모든 서비스, SaaS 등에 소프트웨어 기술이 기반이 되듯이.
하지만, LLM을 개발 & 학습을 하여 인프라로 제공할 수 있는 플레이어는 (최소한 당분간은) 그 기술적 난이도 및 학습 비용의 제약으로 인하여 그 숫자가 제한될 것이며, 그 운용 역시 LLM의 운용 (inference) 비용 구조가 기존 소프트웨어와 상당히 다르기 때문에 (즉, 아주 높기 때문에) 시장 구조가 상당히 다르게 형성될 것으로 예상된다.
LLM 인프라 제공 방식
먼저 LLM 인프라의 제공은 크게 아래의 세 가지 방식이 될 것으로 예상된다.
Foundation Model-as-a-Service (FMaaS):
가장 기술적으로 앞선 SOTA (State of the art) 모델을 pay-per-use (혹은 다른 비용 구조의) API 방식으로 제공하는 것이 가장 보편화된 방식이 될 것이며, 현재 Big Tech 중심으로 시장이 형성될 것으로 예상된다. (OpenAi는 Microsoft를 통하여)
대부분의 ‘AI 기반 서비스’는 이 FMaaS 서비스 API 기반으로 운용될 것으로 예상되며, 그 결과 이들 ‘AI 기반 서비스’를 통해 만들어지는 가치의 상당 부분이 (B2C/B2B 모두 포함, 매출액 대비 10~30% 규모 예상) FMaaS 사업자의 몫이 될 것이다.
‘LLM 기반 비즈니스에서 창출되는 가치 (value accrual)의 가장 많은 부분을 인프라 제공자가 차지할 것’이라는 a16z의 분석에 100% 동의하기는 어렵지만, 적어도 창출되는 전체 가치의 10–30% 정도를 FMaaS 사업자가 차지할 것으로 보인다. 모델 학습 뿐 아니라 모델 운용 (inference)에도 지속적으로 상당한 비용이 필요하기 때문. (예: 검색 기준으로 보면, ChatGPT 기반 검색의 단위 비용이 구글 검색의 수십~수백배에 이를 것으로 추정됨)
오픈소스 LLM:
현재의 LLM 경쟁 상황으로 볼 때, SOTA LLM 모델은 더 이상 오픈소스 (OSS)로 공개하지 않는 방향으로 시장이 변화하고 있다.
그 결과, SOTA LLM 모델 대비 1–2세대 이전 & 상대적으로 작은 규모의 LM 모델만이 소스코드 & 학습된 모델 형태로 OSS로 제공될 것이며, 이를 기업, 서비스 사업자가 원하는 방식으로 (on-premise, FMaaS 등) 사용할 것으로 예상된다.
이 기반의 비즈 모델은, (1) Linux 시절의 Red Hat Linux 같은 컨설팅, 솔루션 제공, (2) vertical 별로 학습된 LLM을 API, SasS 형태로 제공 방식 (아래의 ‘특회된 LLM’ 참조) 등이 모두 등장할 듯 하다.
현 시점에서는 Google PaLM, Adept ACT-1, Stable Diffusion 등이 그 대표적 예이다.
Vertical, 기능별로 특화된 LLM:
다양한 ‘AI 기반 서비스’ 혹은 vertical 별로 기업 시장에 AI가 적용되면서, 각 vertical, 기능별로 특화된 LLM이 제공될 것으로 예상된다.
코딩 분야 Copilot, 검색 분야 Neeva, RPA 분야의 Adept가 현재 시점의 주요 플레이어이며, 시장이 확대되면서 법률, 의학 등 다양한 분야로 확대될 것으로 보인다.
LLM은 SOTA 모델이 별도로 개발되기도 하고, 보편적 FM 기반으로 추가 학습 (domain-specific pre-training) 혹은 (supervised) fine-tuning 등을 통한 vertical 모델 개발, SOTA 모델보다 1–2세대 전 LLM을 솔루션/서비스 형태로 제공되는 등 다양한 형태로 제공될 것으로 보인다.
제공 방식도, API 외에도 솔루션 (paid, royalty, R/S), 마켓플레이스 등 다양한 형태의 비즈 모델이 등장할 것으로 예상된다.
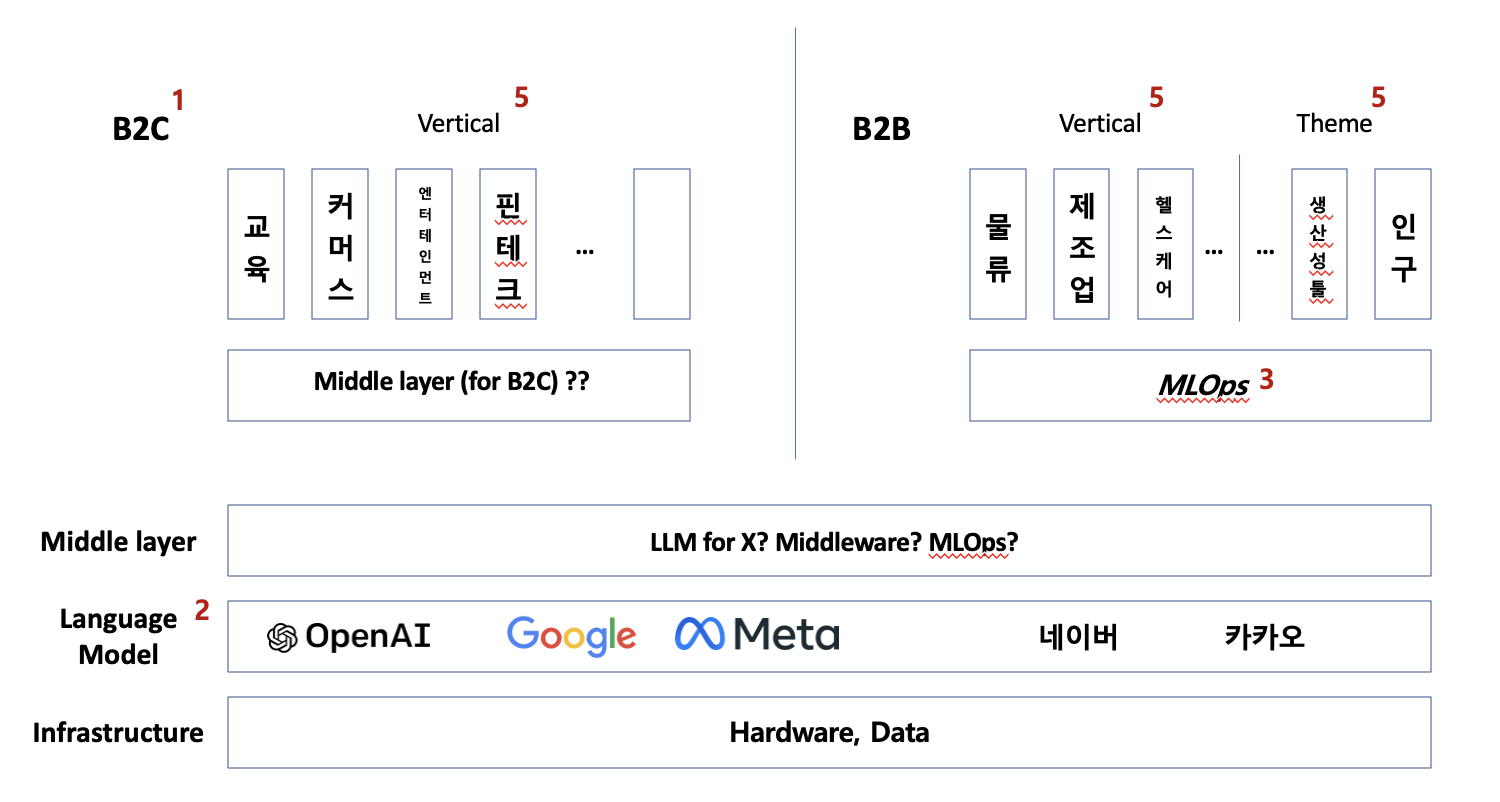
“Middle Layer”
특히, 이 영역에서의 비즈 모델, 플레이어 간의 역할과 관계가 가장 dynamic하게 일어날 것으로 예상된다.
‘AI 기반 서비스’들 (예: Jasper, Lensa) 등이 Consumer향 horizontal 서비스를 제공하는 것 대비, 이 영역은 vertical 시장 별, 혹은 Enterprise 별로 특화되어 제공될 것으로 본다.
추정해 보자면, vertical 별 ‘AI 기반 서비스’ 구축 및 기업 시장에서의 AI 활용 등에 필요한 공통 인프라가 middle layer 화 & 비즈니스 인프라화 될 가능성이 높으며, 이는 빅데이터 시장에서의 Snowflake, Redis, Cloudfare 등의 사업자와 비슷한 포지셔닝이 되지 않을까 한다. 이 layer는 한편으로는 MLOps에 해당하는 부분이 많겠지만, 추가로 vertical에 맞는 추가 학습 (domain-specific pre-training, fine-tuning)에 의한 data moat까지 포함하는 서비스.플랫폼 제공자 역할까지 할 수 있을 것으로 본다.
Gen AI 시장의 초기에는, AI 기반 B2C 서비스가 대부분의 주목을 받고 있지만, 시간이 지나면서 AI 기술이 (B2C 외에도) B2B에도 보편적 인프라화 하면서 이러한 B2B 인프라가 등장할 것으로 예상된다. 기업에 소프트웨어 보급이 보편화되면서 Salesforce, 빅데이터가 보편화되면서 Snowflake가 등장하여듯이.
(아주 거칠긴 하지만, 자체적으로 예상하는 시장 구조에서 middle layer로 표시한 영역)
이러한 LLM 모델 기반 시장 구조의 변화 방향에 대하여, (실리콘밸리의 가장 성공적인 엔젤 투자자) Elad Gil의 글이 많은 insight를 준다. 참고해 보면 좋을 듯.
AI Revolution — Transformers and Large Language Models (LLMs) — Elad Gil
지난 10여년 간의 ‘모바일 wave’에 비추어, Transformer, LLM 기술 기반으로 새로운 ‘AI wave’와 관련 기회가 어떻게 만들어질지에 대한 생각.
AI Platforms, Markets, & Open Source — by Elad Gil
향후 몇 년간 LLM을 둘러싼 시장 구조가 어떻게 전개될 지에 대한 몇 가지 시나리오
LLM 시장 구조
FM 인프라는, 최소 $100m 내지 $1b 규모의 초기 투자가 필요하다. GPT-3의 1회 학습 비용이 $10~20m 규모로 추정되며, 구글에 대적할만 한 검색 데이터 학습 비용이 대략 $50m 규모로 추정된다. GPT-4 혹은 이후 세대의 FM 학습 비용은 최소 $100m 에서 $몇b 규모에 이를 것이다. Moore의 법칙에 의하여 AI 반도체 가격이 계속 하락하는 것을 고려하더라도.
이는 이 시장이 3–5개의 major 플레이어 중심으로 자리잡을 것이라는 것의 의미하며, 90년대 인터넷 및 데이터 센터 인프라 사업자와 유사한 역할을 할 것이다. 따라서, FM 인프라는 이미 Big Tech 중심으로 시장이 구축되고 있으며, 최소 향후 3–5년 OpenAI+마이크로소프트, 구글, Meta 3강 + Amazon, Apple 등의 2~3중 구조가 될 듯 하다.
LLM 학습 비용 구조를 보면, 성능의 마지막 20% 개선에 비용의 80%가 필요한 Reverse Pareto 구조를 띄게 된다.
그렇기 때문에, SOTA LLM은 가장 보편적 FMaaS 인프라로서 계속 ‘메이저 플레이어’의 대표적 FMaaS로 제공되겠지만, vertical 시장에서의 LM 니즈는 그 1–2세대 이전 모델 (현재 기준으로는 변수 10b~30b 규모)로도 대부분 충족될 수 있다.
그렇기 때문에, SOTA LLM은 계속 (현재의 OpenAI GPT-3 API와 같은, OSS가 아닌, API 접근이 가능한) FMaaS 서비스로 제공될 것으로 예상되며, 그보다 작은 규모의 LM은 OSS (코스, 학습된 모델 모두) 형태, 이를 다시 domain-specific 학습 & fine-tuning 되어 다시 FMaaS로 제공되는 방식 등이 혼재할 것으로 예상된다.
후자의 경우, 이들은 각 vertical, 특화 영역별 경쟁력 (예: data moat, workflow, 사용자 이해 등) 기반으로 시장에서 승부할 것이며, 현재 기술 수준에서 Stable Diffusion OSS 모델 학습 비용이 $600k 규모, 특정 vertical에서는 single GPU 기반으로 학습 가능한 모델이 나올 정도인 점을 보면, 앞으로 3–5년간은 이러한 모델의 난립이 계속 될 것으로 보인다. 이 중에 몇 곳이 (예를 들면, 특정 vertical에 특화된) major 플레이어로 등장할 수도 있다.
이러한 다양한 플레이어가 시장에서 어떻게 살아 남아서 의미있는 비즈니스 기반이 될 지는 두고 보아야겠지만, 90년대 CDN 분야 Akamai가 특정 시장을 만들고 메이저 플레이어로 성장한 점이 시사하는 바가 크다. (CDN은 웹 페이지 로드 성능에 큰 영향을 주는 동영상 등의 미디어를 가장 빠르게 제공하기 위한, 일종의 컨텐츠 cache를 위한 네트워크 인프라이다) 즉, 시장의 성장에 따라 (지금은 미처 구분하기 어려운) 아주 좁은 niche 영역에서도 value-capture에 의한 큰 비즈니스 기회가 다양하게 생겨날 것이다.
한글 LLM 환경에 따른 변수
국내시장에 영향을 줄 한글 LLM 분야에 국한해서 보면, 네이버, 카카오 외에는 메이저 플랫폼이 나오기 어려울 것으로 예상된다.
가장 핵심 이슈는, 학습 데이터. 네이버, 카카오는 외부에서 크롤링 가능하지 않은 대규모 고유 한글 데이터를 보유한 유일한 곳이기 때문이다. 그 외의 한글 데이터는 (1) 모든 데이터를 다 모아도 의미있는 규모가 안 되고, (2) 크롤링 가능한 데이터는 이미 글로벌 crawl data에 다 포함되어 있기 때문에, 곧 등장할 GPT-4를 넘어설 수 있는 한국어 pre-training이 더 가능하지 않을 것이라고 본다.
여기에서 국내 환경 관련하여 가장 큰 질문은, (1) GPT-4 내지 그 이후 GPT-N 세대의 LLM에서 한글 데이터에 대한 충분한 학습이 되어 있을지, (2) 국내에서도 SOTA LLM이 제공되고 그 기반으로 충분한 ‘AI 기반 서비스’ 생태계가 구축될 것인가이다.
GPT-4 혹은 이후 세대 LLM에서 한글 데이터 학습이 충분히 된다면, SOTA LLM 기반으로 (vertical 대상) proprietary model, fine-tuning 수준 이상의 추가 한글 데이터 학습이 필요하지 않을 것이고, 이 SOTA LLM 기반으로 국내에서도 ‘AI 기반 서비스’ 생태계가 충분히 만들어질 가능성이 있기 때문이다. (관련된 비용 구조 측면에 대한 논의는 일단 논외로 하고)
그러나, GPT-3에서의 한글 데이터 학습 수준으로 볼 때, 크롤링 가능한 혹은 public domain으로 사용 가능한 한글 데이터가 극도로 제한되어 있는 현재 환경에 큰 변화가 일어날거라 기대하기 어려울 것이기 때문에, 이후 버전 LLM에서도 한글 데이터에 대한 충분한 학습이 되어 있을거라 기대하기는 어렵다고 본다.
이런 환경에서, 네이버, 카카오 이외의 SOTA LLM 모델이 제공되지 않을 경우, 국내에서 다양한 ‘AI 기반 서비스’ 생태계가 만들어질지에 대해서도 큰 의문이 남는다.
또, 현재까지 공개된 자료에 의하면, 네이버 HyperCLOVA는 최대 204b 변수 모델, 카카오 브레인의 6b 변수 모델, SKT의 125m 변수 모델이 국내에서 개발된 대형 LLM 모델로서, 네이버를 제외하면 모두 SOTA 모델 대비 2–3세대 이전 수준에 머물러 있는 점도, 향후 국내에 다양한 ‘AI 기반 서비스’가 만들어질 환경이 만들어질까에 대한 의문이 남는다.
이 이슈가 어떻게 해결되어 국내에 적절한 AI 생태계가 어떻게 만들어질지는 현재로서는 쉽게 결론을 내기 어렵다고 본다.
다만, Chinchilla scaling law 기반의 좀 다른 분석에 의하면, 어쩌면 국내에는 SOTA LLM 경쟁이 필요 없을 수도 있다는 판단이다.
LLM Optimization, MLOps, “Middle Layer” 등
Chinchilla scaling law (좀 더 쉬운 설명)에 의하면, 현재 GPT-3 수준 성능의 모델은 약 30B 변수에 600B 토큰 규모의 데이터 학습으로 가능하며, 이 수준의 모델 학습은 대략 $500k 예산으로 가능하다.
이 의미는 (이 구체적인 수치보다 중요한 점이) 아직 LLM 분야가 기술의 극초기 단계로서 충분한 optimization이 되지 않은 상태임을 의미하고, 이는 향후 몇 년간 LLM 인프라가 서비스용, 기업용으로 확산되면서 (모델의 크기, 학습 데이터 규모, 모델 성능의 극한 경쟁을 하는 SOTA LLM과는 달리) 사용 목적에 맞는 optimization이 상당히 진행될 것이라는 것을 의미한다.
그리고, 이에 사용되는 LM은 당연히 SOTA LLM 보다 1-2세대 이전의 LM 중심으로 시장이 만들어질 것이다.
이 것이 내포하는 몇 가지 의미를 짚어 보면:
당분간은 vertical에 특화된 “Middle Layer”보다는, 아주 일반 모델의 학습, 적용 실험 등이 상당히 광범위하게, dynamic하게, 또 많은 시행 착오를 거치며 진행될 듯 하다. 이 단계에서는 Hugging Face, MosaicML 등의 (vertica에 특화되지 않은) 일반 LM 모델 인프라가 가장 중요한 인프라 역할을 할 것으로 보인다.
이후, 점차 다양한 서비스, vertical, 기업 등으로 확산되면서, domain-specific 데이터로 학습한 모델 및 이 기반으로 비즈니스 use case 및 value prop을 만드는, 소위 “Middle Layer” 플레이어가 다양하게 등장할 듯 하다.
국내에서는 확보 가능한 한글 데이터 규모의 제한으로 인해, 어쩌면 SOTA LLM 모델에 대한 필요가 거의 없을 수도 있다고 본다. 국내에서 가용한 한글 학습 데이터 규모가 1T 규모 LLM 모델 학습에 필요한 만큼 (20T token ~= 30TB) 구하기 어려울 수 있기 때문이다. 그렇다면, 국내 시장에서는 SOTA LLM 경쟁보다는, 1-2세대 이전 LM 기반으로 서비스, 비즈니스 use case 중심의 경쟁이 더 치열할 가능성이 높으며, 이때 가장 중요한 moat는 사용 목적에 맞는 proprietary data의 확보가 될 듯 하다. (어쩌면, 온라인 뉴스, 리디북스 e북 등의 학습용 한글 데이터가 다시 주목을 받을지도)
하드웨어 인프라 측면
메이저 인프라 공급자는, 학습, 추론 두 측면 모두 AWS, Google GCP, MS Azure 3강 외에 대안이 있어 보이지 않는다. (국내의 네이버, 카카오, KT 클라우드 인프라와 같은) 각 시장별 중소 경쟁자가 등장할 수는 있으나, 해당 시장의 niche 플레이어 이상의 의미있는 규모가 나올 수 있을지는 의문이 있다.
LM 운용에 필요한 추론 (inference) 인프라에 대해서는 몇 가지 시나리오가 가능하다고 본다.
점차 추론의 상당 부분 (예: 기본 음성, 이미지 처리)는 많은 부분이 edge device (모바일, PC)에 내장된 inference chip (예: 맥북 M2 Pro 16코어 뉴럴 엔진)에서 처리될 것으로 보이며, Infra-as-a-service는 (1) Vertical 별, 기업별로 특화 학습된 LLM을 인프라와 함께 제공하는 (API, on-premise) vertical 특화된 LLM 제공 사업자, (2) SMB, AI 기반 서비스 등을 위한 ‘Akamai for interence’ 형태의 thin-layer 사업자 등 다양한 형태로 분화될 것으로 예상된다.
AI 반도체 분야:
FM 활용이 보편화되면 추론 (inference) 인프라 수요 규모가 학습 수요보다 궁극적으로 더 커질 것이고, 추론에 필요한 하드웨어 성능 수요가 일반 소프트웨어의 서버 수요 대비 상대적으로 높은 비중을 차지하기 때문에 AI 시장 value-capture에서도 그 비중이 높을 것이기 때문에, 장기적으로 AI 반도체 분야의 성장 전망도 아주 크다고 본다. 국내에도 리벨리온, 퓨리오사 등 주요 플레이어가 제품 개발을 진행하고 있고. (아마, Nvidia와 SOTA high-end 분야에서 경쟁하기 보다는, mid-range 및 edge device를 주 타겟 시장으로 하는 듯) 다만, 나는 AI 반도체 자체를 중점 투자 영역으로 보고 있지 않고 그 시장 구조에 대한 이해도 깊지 않기 때문에, 자세한 분석은 생략한다.
이 분야 투자 기회
이러한 예상에 기반한 이 분야 투자 기회는 아래와 같이 예상된다.
기본 FM 인프라 분야에서는, Big Tech 플랫폼에는 이미 (투자자로서) 접근 가능하지 않으며, (나와 같은 초기 중심) VC로서는 투자 기회로 보기도 어렵다. 이 시장은 이미 실리콘밸리의 메이저 플레이어 및 이에 이미 투자한 일부 VC 외에는 투자 기회가 거의 없다고 본다.
하지만, SOTA FM 이외의 다양한 vertical 별로, 특화된 FM, OSS FM이 지속 등장하며 이 분야에는 어느 정도 의미있는 투자 기회가 남아 있지 않을까 조심스럽게 희망해 본다. 특히 vertical별로 특화된 FM이 API, SaaS, 솔루션 형태로 제공되면 (SaaS 시장의 예로 비추어 볼 때) 통상 vertical 별 Top 3–5 주자들이 그 시장을 과점할 것으로 예상되며 이들이 유의미한 투자 기회가 될 것으로 본다.
하지만, 이들이 얼마나 큰 big bet이 될지는 여전히 의문이 있으며, 특히 이러한 기회가 국내에 (네이버, 카카오를 제외한) 다른 플레이어에게 남아 있을지는 아직 확실하지 않다. 특히 국내의 극도로 제한된 기술 인력 풀을 고려하면 더욱 더.
아직 기술 진보가 필요한 FM 분야가 많이 남아 있다. 로보틱스, multi-modal, reasoning 등이 아직 현재 수준의 LLM으로 다 커버되지 않는 미개척/미완성 분야로 남아있다. 이들 분야에서는 향후 10년 이내 새로운 Big winner의 등장 가능성이 크다. 이 분야의 새 플레이어는 Google 등 기존 big tech이 될 수도 있고, ‘새로운 OpenAI’ 같은 새로운 플레이어가 등장할 수도 있으며, 이들은 big bet이 될 것이다.
다만, 국내에 이 분야의 새로운 기술, 스타트업이 등장할 수 있을지에 대해서는, 국내의 인력 풀, 기술 수준, 시장 흐름 등 측면에서 여전히 의문이 있다.
현재까지의 시장 흐름을 보면, Paul Graham이 트위터에서 지적하였듯이 AI 스타트업이 Bay Area에 고도로 집중되어 있는 것고 이는 90년대 인터넷 스타트업이 고도로 집중되어 있었던 것과 거의 같은 상황이다. 어쩌면 90년대 후반 인터넷 스타트업이 (Bay Area에 먼저) 탄생하고, 다른 지역에서 이를 (카피, 벤치마킹하면서) 따라가는 과정이 다시 반복될 듯하다.
2. AI 서비스
‘AI 기반 서비스’
GPT-3, ChatGPT 등장과 함께 수많은 ‘AI 기반 서비스’ 스타트업이 지난 3개월 사이 생겨났지만, 불과 1–2개월 만에 이들 대부분이 다시 사그러 들었다.
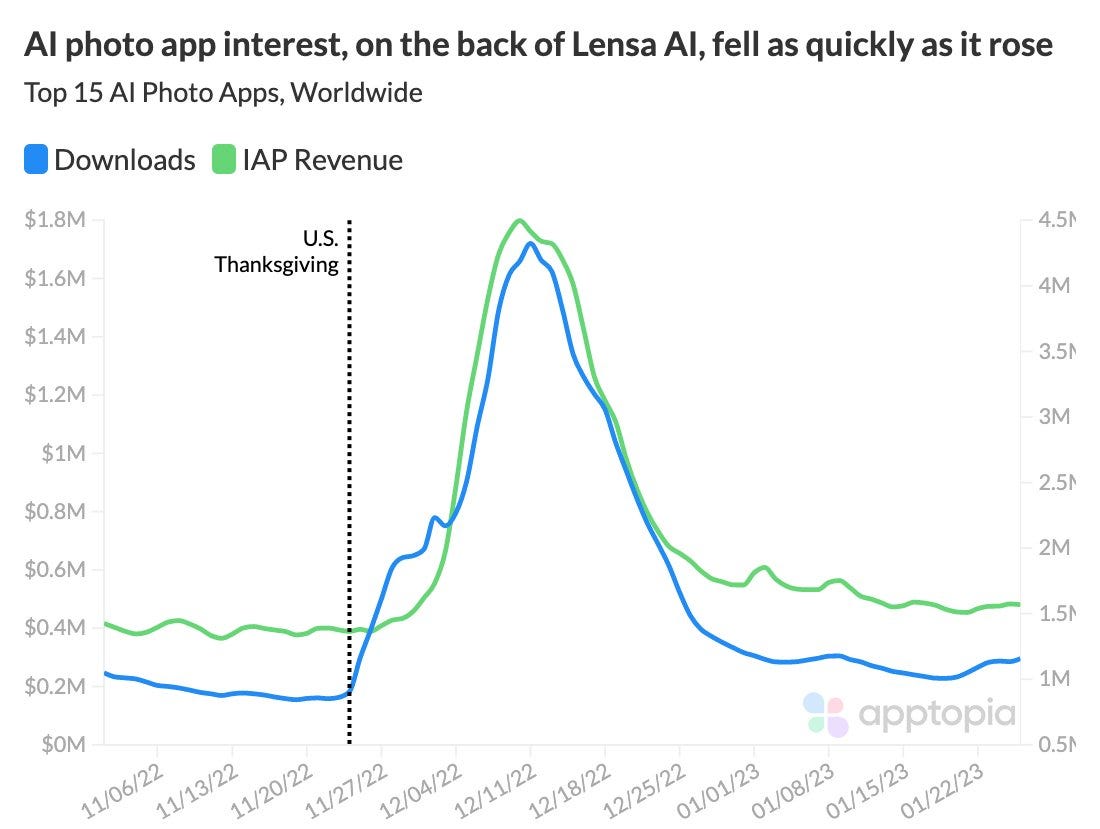
이는, 이들 대부분이 (단순히 GPT-3 API에 UX를 더한) ‘UX arbitrage’에 불과하기 때문이며, 이들 대부분은 (아마 95% 이상) 생존하지 못할 것이다. 이는 94년 Yahoo!, Netscape가 등장하고 consumer 대상 웹 서비스 제공이 가능해지면서, 90년대 후반 수많은 웹 서비스가 등장하고 사라진 시기와 비슷한 패턴을 보일 듯 하다.

이러한 흐름은 두 가지 측면에서 주목할 필요가 있다.
이들 초기 서비스는, 기존에 해 왔던 방식에 새로운 기술을 입혀서 다시 시도해 보는 것이 대부분이며, 이들은 대개 (1) 새로운 기술이 가능하게 하는 새로운 사용 모델을 만들지 못하고, (대부분 비효과적, 비효율적인) 기존 방식에 새 기술을 접목해 보는 시도에 그칠 가능성이 높고, (2) 많은 경우 지속 가능한 비즈니스 모델을 만들지 못할 가능성이 높다.
그 중 일부가 사용자 기반, data moat 등을 확보하면서 시장 경쟁에서 생존하고, 그 중 극히 일부가 이 초기 moat를 leverage하여 다음 단계로 성장해 나가면, 이들 중에 초기 winner가 등장하고 이들이 성공적으로 성장하면 Big Tech 플레이어가 될 수 있다. (예: 1996년 한메일로 초기 사용자를 모으는데 성공하고, 이후 성공적으로 포털로 진화해 간 다음 커뮤니케이션과 같이)
그 data flywheel을 대략 아래와 같이 돌아 갈 것이다.

이 단계의 투자 기회는, 그 수많은 기회 중 미래의 winner를 잘 선택할 것인지가 관건이며, 이는 상당 부분 선구안 + 운이 될 듯 하다.
이러한 ‘AI 기반 툴’ 스타트업에 대한 VC 투자에 대하여 일부 투자자는 상당히 비관적인 시각을 가지고 있고 그 논리의 상당 부분 공감하기도 하지만, 여전히 사용자 기반, data moat를 확보하는 일부 스타트업은 충분히 성장할 수 있는 기회가 있다고 보기 때문에 충분히 적극적으로 투자 기회를 보고 있다. 다만, LLM API 기반 ‘fancy한 UX arbitrage’만으로는 충분하지 않고, 실질적인 고객, 비즈니스 케이스, data moat 전략 등을 통하여 비즈니스의 성장 가능성을 증명하는 것이 중요하다고 본다.
기존 소프트웨어/플랫폼 + AI
동시에, 기존 플레이어의 incremental tech로서 AI 적용이 광범위하게 진행될 것이다.
비유하자면, 보편적 소프트웨어 기술 기반으로 특정 vertical, 생산성 등의 영역에서 value prop을 만들어서 성장하는 SaaS 서비스들과 같이, 기존에 이미 활용되는 서비스, 툴에 AI 기술이 적용되면서 그 효율이 훨씬 높아지는 방식.
기본적으로는, 기존 소프트웨어/SaaS 툴에 AI 기술이 추가되는 방식 (예: Office, Notion, Figma 등), 기존 vertical 혹은 기업용 툴에 AI가 추가되는 방식 (예: Intercom AI 기능) 등이 될 것이며,
동시에 많은 스타트업이 AI 기능을 추가한 새로운 툴을 런칭하겠지만, 기존에 이미 고객, use case가 확보된 기존 서비스 대비 차별화된 value prop을 제공하는 것은 쉽지 않은 uphill battle이 될 것이다.
당연히, 이 분야의 투자 기회는, 이미 있는 소프트웨어/SaaS 투자 thesis에서 크게 달라지지 않을 것이다. (Consumer Sector이든 Enterprise Sector이든)
마치, 소프트웨어가 모든 vertical (커머스, 엔터테인먼트, 생산성 등)에서 새로운 가치를 창출하는 제품.서비스를 만들어 내었지만, 소프트웨어 기술 자체가 투자의 대상이 되기 보다는, 소프트웨어 기술에 기반하여 ‘특정 영역에서 가치를 만드는 제품.서비스 (예: 생산성 툴 SaaS)’가 투자 대상이 되었듯이.
즉, (AI 기술 측면보다는) 기본 서비스 자체가 pain point 해결에 의한 가치 창출 여부, GTM, moat 등에 의하여 성패가 결정될 것이며, 기존 value prop에 AI가 어떻게 더 많은 가치를 만들지, 그리고 팀이 이를 잘 만들고 실행해 갈 수 있을지에 대한 판단이 중심이 될 것이다. 장기적으로는, 점차 AI-native 방식의 툴, 서비스, 소프트웨어가 등장할 것으로 예상되며, 자연스럽게 ‘AI-native 2세대 방식’으로 진화할 것이라고 본다.
2세대 모델의 등장 가능성
하지만, 모든 disruptive technology가 그렇듯이, 새로운 기술은 새로운 방식.behavior에 의하여 그 기술의 잠재 가치가 극대화될 수 있고, 대부분 기술 도입 초기의 이러한 시행 착오를 거친 후 기술 자체의 본질적인 특징을 극대화하는 새로운 방식이 등장하고 이 것이 보편화되면서 새 기술의 본연의 가치가 극대화되는 패턴을 보이게 된다.
90년대 후반의 웹 1.0 시기기도 90년대 말 ‘키워드 검색’ 비즈니스 모델, ‘디지털 아이템 판매’ 모델이 등장하면서, 구글, 네이버, (부분 유료화 기반의) 수많은 서비스 (게임, 소셜 등) 등이 등장하면서 지금의 인터넷 경제 모델이 만들어질 수 있었다. 이 단계가 되어야, 새로운 disruptive 기술에 의한 근본적인 변화와 이에 의한 큰 경제적 변화가 일어나게 되며 ‘훨씬’ 더 큰 투자 기회가 만들어질 것이다. 98년이 되어서야 구글, 네이버가 등장하고 시장을 주도하게 된 것과 비슷하게. (나는 이를 ‘2세대 모델’이라고 표현한다)
물론, 이 과정에서도 (95년에 설립된 아마존의 예와 같이) ‘늘 변하지 않는 소비자의 니즈/욕구’에 집중하여 그 니즈/욕구 충족을 통한 가치 창출에 집중하는 비즈니스도 많이 있을 것이다. (AI 분야에서 추구할 수 있는 ‘늘 변하지 않는 소비자의 니즈/욕구’는 어떤 것이 있을까?)
3. ‘2세대 모델’
이전의 많은 disruptive 기술이 그랬듯이, Generative AI 기술도 그 기술의 본질에 맞는 새로운 모델이 등장하면서 그 잠재력이 최대한 활용되는 ‘2세대’로 진화하게 될 것이라고 본다.
그 ‘2세대 방식’은 어떤 형태, 구조가 될 것인지는 사실상 예상하는 것이 거의 가능하지 않다. 이는 일반적으로 미래를 예측할 때 ‘단기적으로는 낙관적’, ‘장기적으로는 비관적’ 경향을 띄기 때문에 5년 이후의 ‘장기적’ 변화를 예상하는것은 불가능에 가깝기 때문이다. (특히 AI와 같이 그 변화 속도가 상상할 수 없을 정도로 빠른 분야에서는. 현재 LLM의 기술적 기반이 된 Transformer가 발명(?)된 것이 불과 5년밖에 안 된 점에 주목하자)
현재까지의 기술 개발 기반으로, 몇 가지 상상의 나래를 펼쳐 보자면:
자동화된 에이전트 방식. 특히 Adept의 ACT-1이 보여준, 기존 웹 서비스 UX를 모두 자동화하여 사용자의 의도에 따른 결과를 만들어 주는 방식
이를 extrapolate해 보면, “20년 후에는 (지금 우리가 아는 방식의) 웹 페이지는 없어질 것”이라는 예측이 전혀 놀랍지 않다.
특히 보편화된 모바일, ambient 환경 (자동차, TV, 알렉사 등 음성 기반 AI assistants의 부활?, AR/VR? 등)의 UX 접점을 고려하면, 지금 우리가 익숙한 현재의 웹, 모바일 환경과 10년 후의 AI 기반 환경은 완전히 다른 형태가 될 것이 분명하다. 특히 (스스로 학습, 스스로 수정이 가능한) AGI가 보편화될 10–20년 후까지 상상해 보면, 더욱 더.
누군가 “지난 30년간 Web의 시대의 의미는, 새로 등장할 ‘AI의 시대’에 필요한 학습 데이터를 온라인으로 준비해 두는 기간으로서 그 역할을 다 한 셈”이라고 이야기할 정도로.
이 분야의 투자 기회를 미리 예측하기는 불가능하고, 다만 아래의 몇 가지 특징을 가질 것으로 본다.
이 영역이 향후 5–10년간 가장 dynamic하고 가장 새로운 기회가 많이 등장하는 곳이 될 것이며, 어떤 서비스가, 어떤 형태로 등장할 지는 현재로서는 전혀 알 수 없음
90년대 후반에 싸이월드, Facebook, Instagram, Uber, Airbnb, WhatsApp, Snapchat, Tik Tok 같은 서비스의 등장을 예상할 수 있었을까 상상해 보면, 비슷한 느낌일 듯
향후 5년간 기술, 서비스 트렌드의 미묘한 변화, 새로운 (초기에는 허접해 보이는) rookie의 등장 (예: 98년 ‘세이클럽’) 가능성을 지속적으로 주의 깊게 살펴 보면서 판단해야 할 것
결론
Generative AI 분야의 투자 기회는 아래의 몇 가지 특징을 가진다.
한편으로는 90년대 후반 진행된 ‘Web 1.0으로의 전환’ 과정과 (단기적 뿐 아니라 장기적 큰 흐름 측면에서도) 상당히 유사한 패턴을 보일 것으로 예상되며, 동시에 기반 기술, 인프라 등의 경제 구조가 Web 1.0과 (그리고, 당연한 이야기이지만, Web3와도) 상당히 다른 구조이기 때문에, 각 layer 별로 주요 플레이어의 등장 및 시장 장악하는 방식은 꽤 달라질 것이라고 예상된다.
먼저, 기존 방식에서는 클라우드 기반 인프라 제공이 value capture가 크지 않은 상대적으로 단순한 구조의 capex 비즈니스인 것에 비해, FM 인프라 플레이어는 전체 value capture의 상당 부분을 차지하며 그 위 layer 플레이어의 경쟁력에도 직접적으로 영향을 줄 수 있다는 점에서 전체 시장 구조에서 핵심적인 역할을 담당할 것이다.
반면, 앱 layer에서의 value-capture는 상대적으로 비중이 조금 적어질 듯 하다. 특히, 아직은 GPT의 UX layer 형태가 대부분인 ‘AI 기반 서비스’의 value-capture가 앞으로 어떻게 전개될지 지켜 보아야 할 듯 하다. 소위 AI-native한 ‘2세대 모델’이 등장하기 까지는.
어쩌면 Web3에서 중요한 Fat Protocol Thesis가 AI 분야에도 어느 정도 적용되는 듯 하다. Web3 만큼 비중이 극단적이지는 않지만.
추가로, 사용자 및 시장이 이미 Web 1.0, 모바일, Web3 등의 disruptive tech에 의한 산업 및 사회의 변화 과정을 대부분 경험하였기 때문에, 이번 AI에 의한 산업 구조 변화에 대해서는 상당히 ‘informed decision making’을 할 수 있을 것이라고 본다. ChatGPT 등장 후, 불과 한달만에 active user가 1억명을 넘어선 것만 보아도, 시장 플레이어 뿐 아니라 일반 사용자도 이 흐름에 민감하게 반응한다는 것을 알 수 있다.
한달만에 MAU 1억명 돌파한 ChatGPT의 B2C 유료 서비스 런칭, 매주 수십 수백개의 ‘AI 기반 서비스’의 등장 (대부분 2–3일 내지 2–3주 안에 만들 수 있었다고 bragging까지 하면서), 기술적으로 가장 앞서 있으면서도 조심스러운 행보를 해 오던 구글이 떠밀려서 시장에 등장하는 과정, 감히 ‘구글의 검색 시장 과점에의 도전 가능성’에 대한 논란, 거의 매주 새로운 AI 모델의 등장 등등. 지난 12 개월 간 일어난 변화의 속도를 보면, (최소한 실리콘밸리에서는) 이 기회에 대한 FOMO가 이미 상당한 규모로 생긴 듯 하다.
하지만, 대략 10년 싸이클로 투자해야 하는 VC, 특히 국내 시장에서 플레이하는 VC로서는 조금 다른 시각이 필요하였다. 현재의 LLM 기술 경쟁, 수많은 ‘AI 서비스’가 하루에도 수십개씩 생겨나는 상황에 의해 생각이 좌우되는 것을 피하기 위해서라도 최대한 멀리 보는 시각을 가져 보면, 지난 90년대 후반 Web 1.0 전환기에 시장의 구조가 어떻게 변화하였는 지가 현 시점에는 가장 좋은 reference가 되는 듯 하다.
앞으로의 20–30년 AI로 인해 어떤 변화가 올 지 정확히 예측하기는 어렵지만, 최소한 지난 30년간 못지 않은 큰 변화의 여정이 될 것이라는 점은 분명해 보인다.
Bon voyage!
좋은 글 감사드립니다. 깊은 인사이트 배워갑니다!