
[Two Cents #62] Generative AI — 새로운 패러다임, 새로운 큰 '기회'? 어쩌면 '더 큰 위협'?
2023년 들어서도 Gen AI 분야의 큰 변화는 멈추지 않고 계속되고 있습니다.
특히 2023년에는 제가 [Two Cents #58]에서 “2세대 모델”이라고 부른 것의 단초가 될만한 변화들이 보이기 시작했습니다. 이는 기존에 우리가 알고 있는 moat, 성공 방정식을 근본적으로 바꿀 잠재력이 있다고 판단됩니다. 이제 3-4회에 걸쳐 Two Cents에서 이 이야기를 해 보려고 합니다.
그 세 번째 이야기는, 이러한 패러다임 변화가 주는 의미에 대한 생각입니다.
[Two Cents #60], [Two Cents #61]에서 설명한 변화는, 기존 비즈니스와 스타트업 모두에게 큰 새로운 기회와 위협이 동시에 될 수 있다.
이 글에서는 관련하여 3가지 시각에서의 관점을 정리해 본다.
새로운 프로세스/UX는 기회일까, 위협일까?
LLM 기반 새로운 tech stack에서 value-accrual은 어떻게 일어날까?
국내 시장에서 과연 ‘한글’은 어떤 의미를 가질까?
새로운 프로세스/UX의 기회와 위협
가장 먼저, 시스템과 사용자 간의 interaction이 근본적으로 변하는 “Death of UX”, 서비스를 만드는 과정 및 방식이 완전히 바뀌는 “Death of Programming”은 지난 20년간 웹, 모바일 패러다임을 통해 우리가 축적해 온 방식 (서비스 정의, 개발, UX, A/B 테스팅 등)에 대하여, 새로운 방식에 맞는지 모든 것을 의심해야 한다는 것을 의미한다. (”Un-learn”)
예를 들면, 먼저 웹, 모바일 UX가 사라지고 자연어가 기본 input-output이 되면서 UX, A/B 테스팅이 의미가 없어졌고,
(ChatGPT coding을 통해) 1회 사용하고 버릴 수 있는 앱/서비스도 가능해졌고 (”1회용 서비스”, “1회용 UX”),
Chegg 주식에 일어났던 일와 같이 일부 기존 서비스에게는 새로운 방식이 직접적인 “존재에 대한 위협 (existential threats)”가 될 수 있고,
ChatGPT plugin 중 단순 B2C aggregator는 이제까지 구축해 온 moat가 순식간에 큰 의미가 없어질 수 있다. (OpenAI는 “plugin의 서비스와 직접 경쟁하는 B2C 서비스를 만들 의사가 없다”고 강조하고 있는데, OpenAI는 사실 B2C에 직접 진입할 의사가 없겠지만 다른 기존/신규 경쟁자도 그럴 것이라 보기는 어렵다.)
이는 거꾸로, (Chegg의 tutor pool과 같은) 기존 사업자의 moat가 순식간에 사라졌기 때문에 이들 기존 사업자와 경쟁하려는 신규 시장 진입자에게는 새로운 경쟁 규칙 하에서 새로운 green field에서 경쟁할 기회가 생겼다고 볼 수 있다. 다만 여기에 적용되는 경쟁 우위는 아직 어느 누구도 해답을 찾지 못한 상태에서 완전히 새로 만들어지는 규칙 하에서 많은 플레이어가 같은 출발선에서 새로 출발하게 되었다고 볼 수 있다.
한 가지 예를 들면, 기존에 신규 사업자가 시장에서 새로운 사용자를 찾기 위하여 (구글 / 네이버) SEO와 (페이스북, 인스타그램) performance marketing이 필수였지만, 새 환경에서는 구글 SEO와 퍼포먼스 마케팅을 대체할 새로운 공식 (a.k.a. “ChatGPT AI Optimization” (AIO?))을 찾아야 하듯이. (”Re-learn”)
이제 SEO, performance marketing, A/B testing 등 기존 방식 중 상당 부분은 근본적으로 그 의미를 다시 따져 보아야 할 것이고, 기존에 moat라고 생각하고 있는 것들에 대해서도 계속 그 moat가 유지될지에 대한 근본적 고민이 필요할 것이다.
이는 기존 사업자에게는 상당한 새로운 위협이 될 것이고, 새로운 시장 진입자에게는 다시 열리는 기회의 땅이 될 가능성이 높다.
하지만, 많은 사람들이 AI 툴, Midjourney의 등장으로 Adobe가 가장 먼저 위협받을 거라 예상하였지만, 오히려 Adobe Firefly, Generative Fill 등 AI 기술을 활용하여 본인의 강점을 확대시키는 방향으로 빠르게 변신함으로써 오히려 기존 사용자 층 기반으로 더 강한 moat를 만드는 경우도 있다. Salesforce가 기업용 AI 툴 모음 AI Cloud로 빠르게 시장 장악을 시작한 것도 같은 맥락으로 볼 수 있을 것이다.
결국 AI가 기회가 될지, 위협이 될지는 기존 사업자, 신규 진입자 모두 스스로의 moat와 AI의 결합을 얼마나 잘 찾아 내는가에 따라 달라질 것이다. (너무 원론적인 이야기이긴 하지만)
[MESSAGE FROM SPONSOR]
[AI 트렌드 세미나 #3] Generative AI — 새로 열린 '큰 기회', 혹은 '어쩌면 더 큰 위협'
“생성 AI의 해”라 할만 한 2022년이 지나고, 2023년에도 놀랄만한 변화가 계속되고 있습니다. 특히 2023년에는 제가 [Two Cents #58]에서 “2세대 모델”이라고 부른 것의 단초가 될만한 변화들이 보이기 시작했습니다.
당연히 이런 큰 변화는 기존 비즈니스, 새 스타트업 모두에게 아주 큰 ‘기회’가 되면서, 동시에 어쩌면 ‘더 큰 위협’이 될 수도 있습니다.
이 AI 트렌드 세미나에서는 이 이야기를 해 보려고 합니다.
주제: Generative AI — 새로 열린 '큰 기회', 혹은 '어쩌면 더 큰 위협'
AI와 다시 열린 “서부 개척 시대”
기존 비즈니스, 스타트업에게는 어떤 큰 ‘기회’가?
어쩌면 ‘더 큰 위협도’?
몇 가지 suggestions
새로운 LLM stack의 economics
아직은 산업의 극초기이기 때문에 stakeholder들 간에 value가 어떻게 배분될 지에 대한 시행착오를 많이 거칠 것이다.
가장 먼저 주목받는 것은, LLM이 차지할 value-accrual의 비중인데, 아래의 경우들이 있다.
(API 가격 체계를 통해) 이를 이용한 다른 사업자의 매출 중 LLM이 차지할 비중
ChatGPT plugin 파트너와 LLM 간의 수익 배분 구조
외부 검색, 데이터베이스, API 파트너를 LLM이 접근할 때 수익 배분 구조 등.
LLM은 (1) (개념적으로는) 학습 데이터를 통해 그 고객의 비즈니스 로직의 일부가 LLM에 내장되어 있는 셈이라고 볼 수 있고, (2) 이를 이용하는 inference 과정도 (일반적인 클라우드 서버 & SW 스택 대비) 높은 computing power를 요구하기 때문에, 그 고객 (특히 B2B)의 LLM 의존도가 높고 그 비용도 높을 수 밖에 없다.
따라서, LLM 인프라는 전체 stack에서 발생하는 value-add에서 차지하는 비율이 높을 수 밖에 없다. 클라우드 인프라가 차지하는 비중이 통상 10%를 넘지 않는 것 대비, LLM은 적어도 10~30%, 어쩌면 그보다 높은 (최대 50%까지) value-accrual을 차지할 수 있다.
LLM 중심 시각에서 보면, (1) LLM을 core에 두고 “small app” 들이 thin layer를 만들고 아주 낮은 비중의 value-accrual를 차지하는 구조, 혹은 (2) LLM front-end에 (plugin API를 통해) 기존 B2C 서비스가 API backend 역할을 하는 구조로 갈 가능성이 크다.
이 두 가지가 현재 ChatGPT plugin 및 API 중심으로 만들어지고 있는 생태계 구조이며, 이 경우 어쩌면 50%에 가까운 value-accrual을 LLM이 가져 갈 수도 있다. (Web3에서 생겨난 “Fat Protocol Thesis”가 LLM에서도 유효하다고 볼 수도 있다. 여기에서는 토큰이라는 가치 교환 매체를 통하지 않지만)
아직 개념 정립조차 되어 있지 않지만, (Autonomous Agent 구조를 통하여) 이와 정반대 형태의 구조도 새롭게 등장하고 있고, 두 가지 방식 중 어떤 방식이 앞으로 주류를 이룰지에 대한 논의가 이제 막 시작된 단계이다.
LLM Core, Code shell: (Langchain, ChatGPT plugin API, function 호출기능 등) 기존 방식
LLM Shell, Code Core: (Autonomous Agent, Voyager model 등) 새롭게 등장하고 있는 방식

이 중 어느 한 방식이 시장을 dominate하지 않고 두 방식이 공존할 가능성이 크지만, 각각 LLM 기반 app, 서비스의 value-accural에 큰 영향을 미칠 것이고, 결과적으로 새로운 스타트업에게는 큰 기회가 될 수도, 큰 위협이 될 수도 있겠다. (아직은 너무 시장 형성 초기라서, 아직은 이 이상의 분석이나 예측을 하기 어렵다.)
한글의 defensibility
90년대 후반 Web이 처음 도입될 때에는, 그래도 ‘한글’이 국내 업체에게 꽤 중요한 진입 장벽 역할을 해 주었다.
이번 Gen AI 시대에도 같은 질문을 던질 수 있는데, 지금까지의 판단으로는 “Not likely”이다.
먼저, GPT-4의 한글 능력은 (77%) GPT-3.5의 영어 능력 (70%)보다 높다. 즉, proprietary data 없이 public data만으로 학습한 GPT-4의 한글 능력이 생각보다 높다.
물론, 아직 GPT-4도 영어의 85.5% 대비 꽤 낮고, GPT-4를 제외한 다른 모델 (GPT-3.5 포함하여, 대부분의 중규모 LLM)에서는 한글 능력이 많이 떨어지기 때문에 아직은 시장 기회가 있지만, 그 기회가 2-3년 이상 유지될 것이라 보기는 어렵다.
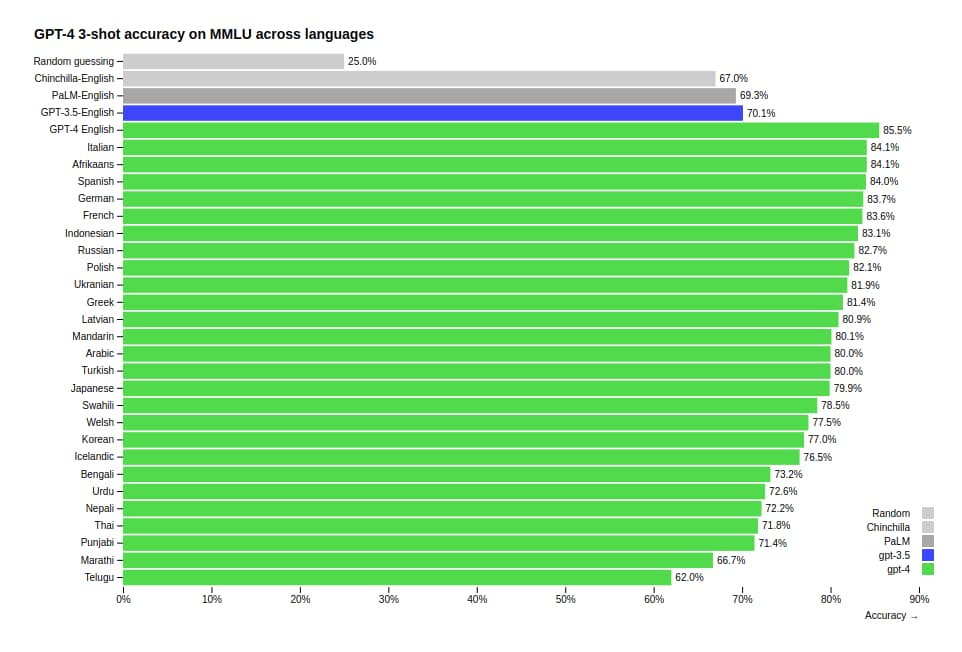
또, 학습에 사용할 수 있는 한글 데이터는, 네이버, 카카오 내부에 있는 데이터까지 다 포함해도 최대 1~2T 토큰 내외이고 네이버/카카오 내부 데이터를 제외하면 그 1/4 규모에 불과해, 결국 학습에 사용할 수 있는 한글 데이터는 GPT-4 학습에 필요한 수준에 머무른다는 점이, 앞으로 더 큰 한글 SOTA VLLM을 개발하는데 큰 제약이 될 것이다.
많은 사람들의 기대와 달리, LLM이 생성해 낸 데이터는 (instruction tuning 정도까지는 의미가 있지만) LLM base model의 학습용으로는 적절하지 않다. 생성된 데이터로는 기본 모델의 emergent 능력을 만들어내지 못하고, 생성된 데이터 기반 학습이 반복될 경우 overfitting에 의한 bias가 심해지기 때문이다.
이미 웹 상의 영문 데이터에서도 LLM 생성 데이터에 의한 “오염”이 이미 시작되었다고 보며, 고품질의 학습 데이터의 가용성는 영문, 한글 모두 앞으로 점차 더 어려운 이슈가 될 것이다.
이를 고려하면, 현실적으로는 한글 데이터에 기반한 경쟁력은 중규모 LLM 기반으로 on premise, private, 혹은 특정 목적에 특화된 용도에 제한될 것으로 추정되며, 이러한 환경에 대응하는 moat 전략을 수립할 필요가 있다고 본다.
이러한 변화는 향후 1-2년간 단기적으로 일어날 변화라기 보다는 3-5년, 길게는 10년의 기간 동안 일어날 큰 변화의 방향이다.
기존 비즈니스, 새로운 스타트업 모두 이러한 큰 변화의 흐름 속에서, 단기적으로 찾아서 극대화해야 할 기회가 있을 것이고, 장기적으로 이 큰 변화의 흐름을 어떻게 타야 할까에 대한 고민도 있을 것이다.
이러한 변화 속에서 moat는 어떻게 변화하고, 그에 따라 단기적으로 그리고 장기적으로 어떤 기회가 있을까?
아직 산업의 극초기로서 그 정답을 찾기는 극히 어렵겠지만, 최소한 그 원칙, 방향성에 대한 논의를 계속해 보자.
[To be continued]