
[Two Cents #82] “Flights of Thought” on Consumer + AI — Part 8: Personalization
Consumer AI에 대한 ‘시장의 준비’가 tipping point를 넘어 가고 있는 것으로 보인다.
지금 필요한 일은, AI 기술에 의한 시장 변화가 어떤 방향, 어떤 방식으로 일어나고 그 것이 (산업 및 시장의 구조, 시장 참여자 간의 구도 및 economics 구조 등에) 어떤 영향을 가져 올 지에 대하여 최대한 구체적으로 예상, 예측해 보고,
그 과정에서 예상 가능한 기회를 조금이라도 먼저 찾고 시작하고 (스타트업 입장에서), 마찬가지로 이렇게 시작한 기회를 먼저 인지하고 이를 지원하는 (투자자 입장에서) 것이 필요하다고 본다.
이 흐름과 과정에서 일어날 다양한 ‘것’들, 관련된 아이디어들에 대한 나의 생각의 흐름 (”Flights of Thought”)을 공유 하려고 한다.
이번에는, Consumer AI 분야에서 가장 ‘중요한’ 핵심 인프라 혹은 플랫폼 역할을 할 것으로 예상되는 “personalization layer”에 대한 생각이다.
원래는 각 분야, vertical 별로 새로운 기회에 대한 생각 이전에 정리하고자 하였지만, 생각을 정리하기 쉽지 않아서 미루었고, 아직 완성된 생각이라 하기는 어렵지만 현재 단계에서는 이 수준에서의 고민이라도 시작하면 좋겠다는 생각으로 정리하였다.
‘개인화 (personalization)’에 대하여
Gen AI 기술로 비로소 가능하게 된 것으로, (인간 개인이 소화하기에는 너무나 거대한) 지식을 기반으로 한 분 및 생성 (Transformer 기반), 그리고 “무한히 다양하게 개인화된 (컨텐츠) 생성”을 “(거의) zero marginal cost”로 가능하게 (Diffusion Model 기반 이미지/동영상, Tranformer 기반 코드/UX 등) 된 것이라 볼 수 있다. “개인화”된 “무한한 생성”를 “(거의) zero marginal cost”로 가능하게 된 것은, 초기에는 이미지, 동영상 생성으로 시작되어, 지금은 그 다음 단계로 게임, 3D World Model, 소프트웨어 (aka “vibe coding”) 생성 분야로 확장되고 있다.
이러한 변화가 소비자가 “시스템 (그게 무엇을 의미하던지)”과 interaction하는 접점, 그리고 그 interaction 방식에까지 미치게 되면, 이를 “개인화 (personalization)”이라고 부를 수 있다.
그러한 대표적 케이스가 [Two Cents #81]에서 다룬, 향후 교육 분야에서 가능해질 것으로 기대되는 “초개인화된, 무한한 선택 기반의, 인생 전반에 걸친 학습” 방식이다.
현재 단계에서도 “시스템” (여기에서는 AI 서비스, 챗봇, app 등)의 “개인화”는 이미 어느 정도 진척이 있다.
ChatGPT를 사용할수록 과거 대화와 그 맥락 (예: 내가 어떤 일을 하고 있고, 어디에 출장을 간 상태이고, 등)을 기억하고 그에 맞는 사용자 경험 (예: 과거 prompt 대화 기반으로, prompt 명령 없이 데이터만 입력하여도 알아서 원하는 결과를 만들어 주는 등)을 제공하고 있고, 이 것이 누적되면 이제 (ChatGPT, Claude, Gemini 등) LLM 챗봇 간의 switching cost가 높아지게 된다. 이 것이 현재 수준의 (LLM 챗봇) “개인화”라고 볼 수 있다.
ChatGPT의 memory를 들여다 보면, 과거 내가 입력한 prompt 중에서 (ChatGPT의 판단으로) 나에 대한 “맥락 (context)”가 될 만한 내용을 추출하여 “memory”에 저장해 두고, 이를 prompt context로 사용하는 아주 초보적인 수준이지만, 그럼에도 이 정도의 ‘개인화’만으로도 챗봇 경쟁에서 어느 정도의 lock-in 효과를 보일 정도이다.
이러한 경험을 확장하여, 개인화를 위한 infra를 구축하고 이를 “OpenAI Account” 형태로 wrapping하여 소비자들을 lock-in 하는 것이, 현재 OpenAI가 드라이브하는 “개인화”의 기본 전략이라고 본다. “개인화를 위한 infra는, 현재 기술 수준에서는 context memory 방식으로 시작하여, 장기적으로 좀 더 정교한 “personalization data layer” 기반으로 확장될 것으로 예상되는 데, 이는 ChatGPT를 전면에 내세워 Consumer 대상 “AI Super app”으로서 만들고자 하는 OpenAI의 소비자 대상 전략의 core 기술/인프라가 될 것으로 본다.
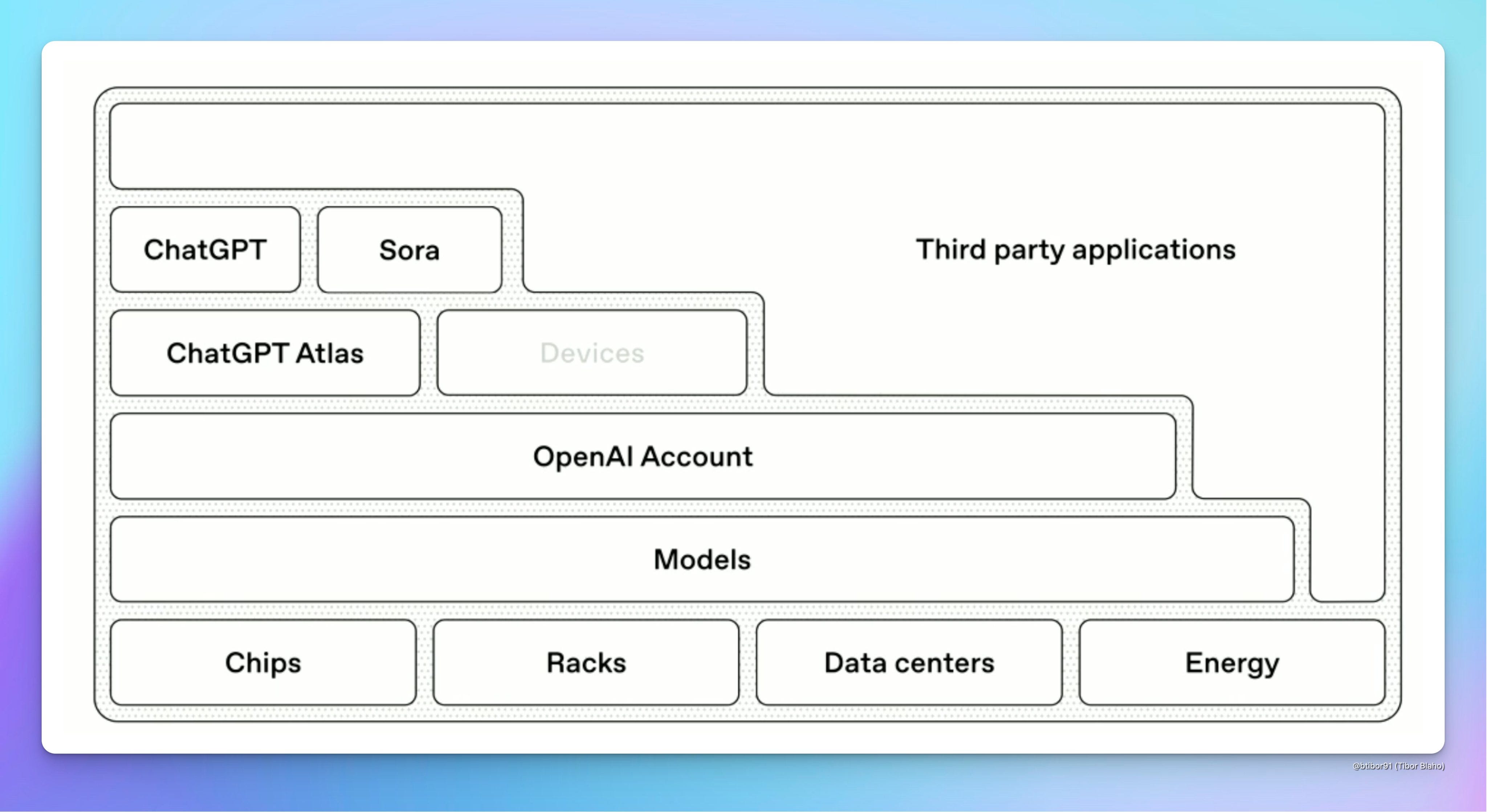
이제 ‘개인화’가 AI 기반 “시스템” (AI 서비스, app, 인프라, ambient 환경 등을 포괄하는 개념으로)까지 확장되면 어떤 일이 일어날 지 상상해 보자.
‘개인화’ 유형과 그 의미
‘개인화’ 관련 방식과 기술은, 앞으로 오랜 시간동안 (10년?) 다양한 방식이 등장하고 그중 일부의 기술 및 방식으로 수렴할 것이며, 그 양태는 아래 몇 가지의 특징을 가질 것으로 본다.
나에 대한 맥락에 대하여 이해하고, (그 범위, 그 깊이에 대해서는 아래애서 좀 더 살펴 볼 것임)
그 맥락/이해를 기반으로 나의 의도를 이해하고, (내가 그 의도를 표현한 것 기반 (reactive), 혹은 표현하지 않더라도 (pro-active, prescriptive))
그에 맞게 ‘개인화’된 UX를 기반으로 (아래 Conformative Software 참조)
나의 의도에 맞는 (’개인화’된 결과를 제공하는) 서비스를 제공
그리고, 이러한 ‘개인화’는 사용자 경험, interaction 등에 대하여, 지난 30년간 경험하였던 (기초적인 수준의) ‘개인화’와는 근본적으로 다른 깊이, 스케일의 큰 변화를 가져 올 것으로 예상된다.
개인화의 단계: favorites → recommendations → delegation/autonomy → pro-active, prescriptive
과거 개인화의 형태는 (사용자가 자신이 원하는 것들을 저장해 두는) favorites 형태 중심이었고 (예: 음악 playlist)
이 것이 (사용자의 과거 사용 패턴, 혹은 같은 취향의 다른 사용자의 패턴에 따라) 추천 시스템으로 진화하였다. (예: YouTube 음악 자동 추천)
지금부터의 AI 기반 개인화는 크게 두 가지 형태로 나누어질 것으로 본다.
autonomy/delegation: “나의 맥락을 아는” AI 혹은 agent에게 내가 원하는 task를 맡기고 그 결과를 기대하는 reactive한 개인화 (예: “내 취향에 맞춰서 이번 주말 OO 파티에 입고 갈 드레스 찾아/추천해 줘”. “이번 주말에 막내 포함하여 2박3일 가족 여행 가려 하니, 여행 일정 짜고 예약해 줘”)
pro-active/prescriptive: “나의 맥락을 아는” AI 혹은 Ambient Agent가 내가 해야 할 일을 먼저 알려 주는 pro-active 개인화 (예: 나와 가족의 일정을 알고 있는 “집사 agent”가 “다음 주말 막내 아들의 OO 학교 행사에 참석하려면 OOO 준비물이 필요한데, 미리 주문해 둘까요?”라고 물어 오는)
이러한 개인화는 다양한 구성 요소 및 형태로 구현될 것으로 예상된다.
Personalized “agents”
나의 맥락을 입력/기억하고, 그에 따라 나의 ‘개인화’된 니즈를 serving하는 agent
개별 서비스마다 나와의 과거 interaction을 기억하는 개인화된 agent가 (혹은, 개인화 module이) 있을 수 있고 (per system),
(특정 서비스가 아닌) 나 개인에게 소속되어 나의 맥락을 다 기억하고 있고, 나의 니즈에 따라 개별 외부 서비스에 대하여 (나를 대행해서) 일을 처리하고 (reactive), 또 내게 할 일을 먼저 알려 주는 (pro-active), ‘나의 life-time partner로서의 agent’ 일수도 있고 (per person)
“Conformative software”: 나와의 interaction에 따라, 나를 대하는 방식, UX 등이 진화하는 형태의 UX를 가진 소프트웨어 혹은 ”시스템”. 나와의 대화에 따라 개인화되어 진화하는 현재의 ChatGPT가 그 가장 초보적인 형태라고 볼 수 있다.
on-device vs. cloud-based
이러한 agent (per system 혹은 life-time partner로서)가 내 아이폰에 상주하거나 (on-device), 클라우드에 상주하거나 (cloud-based, ambient agent),
“Collective memory”: 나 개인에 대한 ‘개인화’에 그치지 않고, 나의 ‘가족’, 나의 ‘직장 동료, 팀’을 포함한 조직 단위의 collective memory를 만들고 이 기반으로 추가로 개인화할 수 있는
이러한 ‘개인화’ 경험이 축적되면, 사용자는 점점 더 “시스템” (챗봇, Ambient Agent, “집사 agent” 등)에 lock-in되어 갈것이다.
특히, 이러한 lock-in 효과는 양방향으로 일어날 것으로 본다.
‘개인화’의 편리함에 익숙해지면서, 사용자는 더 이상 ‘자기를 기억해 주지 않는’ 서비스보다는 ‘자기를 기억해 주는’ 서비스를 지향할 것이고 (you’ll never want be a stranger to a new agent or AI app),
그 과정에서의 나의 모든 의사 결정이 다시 그 “시스템”의 ‘개인화’를 더 강화하는 feedback loop이 될 것이기 때문에, (The benefits of personalization compound over time)
이 과정에서 ‘개인화’는 retention, growth loop을 강화하는 중요한 기제가 될 것이고, 궁극적으로 (‘네트워크 효과’ 못지 않은) 가장 강력한 사용자 lock-in 기제가 될 것이다. (”Personalization effects” are the new “network effects”)
‘개인화’ 데이터, 기술 등
이러한 ‘개인화’를 위하여 필요한 개인 데이터 spectrum은, 생각보다 아주 많거나 복잡할 것으로 보이지는 않으며, 아래의 (Level 5까지는 이미 available하고, 대부분 제한된 형태이긴 하지만 접근 가능한) 데이터들이 가용할 것으로 본다.
Level 1: 이메일, 일정, 나의 문서/자료 (업무용, 개인용, 프로젝트 별 …)
Level 2: 소셜 네트워크 (LinkedIn, FB), 메신저 (카톡, 문자) 대화
Level 3: 쇼핑, 배달 주문, 은행 입출금, 신용카드 등 모든 개인 거래 내역
Level 4: (Google Map에 기록된) 일상에서의 나의 실시간 위치 기록
Level 5: (iCloud에 저장된) 나의 건강 데이터
Level 6: (실시간) 개인 대화/통화, 화면 터치/클릭 데이터 등
Level 7: … (TBD)
관건은,
각 서비스들이 이러한 개인 데이터를 어떻게 확보하고 (특히, Level 4 이상의 데이터를 제3자가 실시간 확보하는 것은 거의 불가능할 것으로 보인다. 다만 Data Portability (데이터 이동권) 법안에 의하여 사용자의 개입 하에 1회 export는 대부분 가능하다),
확보된 데이터를 어떻게 ‘잘 섞고 가공하여’ 실질적으로 ‘개인화’ 효과를 낼 수 있도록 활용할 지,
등의 여러 단계/유형의 challenge가 있다고 본다.
관련하여, 현재 단계 AI 업계에서 실제 일어나고 있는 논의 및 기술 수준을 살펴 보면:
현재 대부분의 서비스는 Stateless Agent(상태 없는 에이전트)나 일회성 워크플로우에 머물러 있음
Sleep-time Compute란, 사용자가 직접 명령하지 않아도 에이전트가 백그라운드에서 데이터를 분석, 메모리 정리, 학습하는 것
Agent 시스템의 핵심 구성요소는 상태(메모리/컨텍스트), 모델, 액션(도구/서버 등). 이중 가장 중요한 것은 ‘상태와 메모리’.
상태와 메모리, 학습 능력이 있는 것이 진정한 에이전트임. 더 자율적이고, 인간처럼 학습하며, 지속적으로 발전하는 존재로서, **“모델보다 수명이 더 긴 Agent”**가 개인의 lifetime partner agent 역할을 할 수도 있음
Stateful Agent의 목표는, 에이전트가 스스로 메모리를 관리하고, 오랜 시간 동안 일관성을 유지하는 것. 진정한 Stateful Agent를 만들기 위해서는 모델 외에 ‘컨텍스트를 관리하는 운영체제(OS)’가 필요. 예: Andrej Karpathy가 언급한 ‘컨텍스트 엔지니어링’ 개념
다양한 시도, 향후 방향
지금 논의되고 있는 Context Engineering은 (그 가장 초보적인 형태의 ChatGPT memory 포함) ‘개인화’에 필요한 ‘personalization data layer’의 첫 번째 형태가 될 것이다.
그 다음 단계의 “personalization data layer”가 어떤 형태로 구축되고, 각 개인의 데이터가 어떻게 모이고/활용되고, 그 것이 실제 어떤 형태로 ‘개인화’를 제공할 지 등의 구조 (architecture, worlflow, UX, data layer model, 개인화 방식/모델 등)에 대해서는, 이제 막 이 분야가 시작하는 단계라서 구조적으로 정리된 것이 아직 없고 모든게 유동적이고 모든 시도들이 각각 다른 구조와 방식으로 진행하고 있다.
실제로, 가까운 과거와 현재, ‘개인화’를 위한 third-party data layer 구축 혹은 ‘개인화 서비스’ 제공을 위한 몇 가지 시도들을 살펴 보면:
Rewind: 맥북의 화면과 기타 데이터를 실시간으로 저장하고, 이를 기반으로 맥락의 retrieval 및 개인화를 시도(”디지털 타임머신” 기능). 프라이버시, 사용자이 느끼는 실제 가치 등에서 한계를 보이고 실패. 지금은 Limitless로 이름을 바꾸어 대화, 회의 기록을 통한 데이터 수집에 집중
mem0: 사용자의 모든 디지털 활동을 기록하고, 이를 기반으로 개인화된 AI 메모, 지식베이스 구축하는 memory layer
Letta: ‘기억’ 능력을 가지는 AI Agent 구축 플랫폼
Poke.com: 개인의 맥락 일부를 받아서 그 개인에 대한 context를 구축하고, 이를 기반으로 개인 대상 ‘개인화’된 AI Assistant 서비스
이러한 시도들의 결과와 그 의미를 해석해 보면:
아직 모든 서비스에 적용 가능한 horizontal personalization data layer를 구축하는 것은, 데이터가 일정 규모로 구축되기 전에는 사용자가 느끼는 value proposition 및 이를 기반으로 하는 비즈니스 모델을 만들기가 상당히 어려워, 사용자 (개인 데이터의 공급자)와 비즈니스 (개인 데이터의 수요자) 양쪽 모두 빠르게 scale-up하기 어려운, 전형적인 two-sided marketplace의 초기 chicken-egg problem을 경험한다는 점이다.
이 점이 Rewind, mem0 등 data layer를 구축하려는 시도 모두 실패하거나, 아직 빠른 성장세를 보여 주지 못하고 있는 배경이라고 본다.
이에 반해서, 최근에 등장한 Poke.com 사례를 보면, ‘개인화’를 기반으로 하되 “사용자가 자신의 개인 데이터를 기꺼이 내어 놓을만한 value prop을 가진 하나의 뽀족한 서비스”에 집중해서 사용자를 먼저 모으고, 일정 규모 이상의 critical mass가 모인 이후 이 데이터 기반의 ‘개인화’를 수평적으로 다른 분야/서비스로까지 확대하는 것은 가능하지 않을까 추정하고 있음. 즉, 특정 서비스가 제공하는 value prop 기반으로 personalization data layer 구축을 장기적으로 확대해 나가는 전략이 가능할 수 있다고 봄
이러한 방식을 좀 다른 시각에서 해석해 보면, 페이스북, 카카오톡 등 massive한 규모의 social network 모두 기본적으로는 “하나의 뽀족한 서비스/value prop”에 집중하여 초기의 사용자 기반을 구축하고 escape velocity를 만들어 냄으로써 현재의 dominant user base를 구축하는데 성공하였다고 보며, personalization data layer와 같은 massive data layer를 구축하기 위해서는, 이러한 (일종의 piggy-back) 전략이 필요하다고 판단된다.
‘Next Google’
이러한 어려움에도 불구하고 (모든 Consumer향 서비스에 적용 가능한) “personalization data layer”를 구축할 수 있다면, 그 플레이어는 소비자의 attention을 모으고, 강한 (그리고, 시간이 지나면서 더욱 강해지는) lock-in 효과를 만들어낼 수 있을 것이라고 본다.
이러한 “data layer” (혹은 ‘플랫폼’)은 점진적으로 사용자의 attention을 더욱 강하게 lock-in할 것이다.
Agent 기반의 AI 환경에서는, 소비자가 자신이 직접하는 일 vs. Agent에게 맡기는 일의 비중이 (현재의 90:10에서) 20:80 수준까지 변화해 갈 것이고, 어쩌면 더 많이 (10:90까지?) 바뀔 수도 있다.
Personalization data layer는 ‘나의 맥락’을 이해하는 ‘개인 컨시어지’ (agent 혹은 서비스)의 ‘핵심 기반’이 될 것이고,
내가 더 오래 사용할 수록 축적되는 ‘나의 맥락’이 더욱 많아지고 이에 기반한 ‘개인화’ 깊이도 더욱 강해질 것이다 (lock-in의 심화)
궁극적인 형태는, 영화 her의 ‘사만다’ 혹은 영화 “남아있는 나날”의 집사 ‘스티븐스’ (앤서니 홉킨스 분)에 해당하는, “나의 의도를 가장 잘 이해하고, 이를 가장 잘 실행해 주는” agent 혹은 서비스가 될 것이고, 이를 위한 가장 중요한 enabling infra가 “personalization data layer”가 될 것이다.
이러한 점에서, 이 “personalization data layer”를 장악하는 플레이어는 (Web 시대의 구글보다도 더 강하게) 소비자의 첫 번째 접점을 장악하게 될 것이고, (구글보다도 더) 강한 lock-in 효과를 가지는 비즈니스 모델을 확보하게 될 것으로 예상된다.
그래서, 나는 개인적으로 “개인화 데이터 layer/agent’ 분야가 (Web 1.0 시대 ‘구글’만큼의, 혹은 그를 뛰어 넘는 영향력을 가지는) 소비자 대상의 dominant platform이 나올 수 있는 기반이 되지 않을까” 한다. 그 구체적인 양태는 앞으로 10년 정도의 시간동안 상당히 dynamic하게 진화해 가겠지만.
Consumer + AI 분야에 집중하는 초기 투자자로서 이러한 생각의 흐름을 공유하는 주된 목적은, 이 글을 통하여 기존 스타트업들이 AI 흐름을 잘 활용하여 어떤 새로운 기회를 찾아 낼 지, 또 새로운 창업자들이 어떤 새로운 기회를 모색하면 좋을 지 고민할 때, 그 시행착오를 줄일 수 있는 하나의 참고 자료가 되기를 바라기 때문이다.
Two Cents 나름 방식의 Call for Startup이라 할 수 있다.
이러한 기회를 찾았다고 생각하는 Consumer + AI 분야 초기 창업자/스타트업들은 언제라도 열려 있으니 DM 혹은 이메일 (hur at hanriverpartners dot com)으로 연락 주시기 바란다.
그 개인화 data layer를 지배하는 플레이어가 meta, Google, Apple 같은 가성 빅태크일까요? 아니면 oai 혹은 새로 나올 스타트업이 될 수 있을까요?
메타 글라스가 최고의 '나에 대한 정보 수집' 디바이스가 될 수 있을 거 같은데, 여전히 배터리가 8시간까지네요.